Операционные системы. Управление ресурсами
Тупики: предупреждение, обнаружение, развязка
Борьба с тупиками включает в себя три задачи:
- предупреждение тупиков - какую стратегию распределения ресурсов выбрать, чтобы тупики не возникали вообще?
- обнаружение тупиков - если не удалось применить стратегию, предупреждающую тупики, то как обнаружить возникший тупик?
- развязка тупиков - если тупик обнаружен, то как от него избавиться?
Возможные стратегии распределения ресурсов располагаются между двумя полюсами - от самых либеральных до самых консервативных. Чем либеральнее стратегия, тем "охотнее" ОС удовлетворяет запросы на ресурсы. Но за слишком либеральную стратегию приходится расплачиваться возможностью возникновения тупика. Консервативные стратегии делают тупики невозможными в принципе, задачи обнаружения и развязки при применении таких стратегий не ставятся, но плата за это - частые отказы в выделении ресурсов, следовательно, снижение уровня мультипрограммирования, а следовательно, - и снижение пропускной способности. Ниже мы будем рассматривать стратегии предотвращения, двигаясь от консервативного полюса к либеральному в таком порядке:
- последовательное выделение;
- залповое выделение;
- иерархическое выделение;
- выделение по предварительным заявкам.
Последовательное выделение.
Любыми ресурсами может одновременно пользоваться только один процесс. Если процесс A из предыдущего примера получил ресурс-принтер, то процессу B будет отказано даже в выделении ресурса-ленты. Очевидно, что такая стратегия делает тупики совершенно невозможными. Очевидно также, что некоторые процессы будут при этом простаивать совершенно неоправданно. Так, например, будет приостановлен некий процесс C, которому принтер и не нужен, а нужна только лента. Поскольку в число распределяемых ресурсов входят устройства ввода-вывода, а работают они медленно (пример - та же печать на принтере), простой может затянуться. Эта стратегия неоправданно снижает уровень мультипрограммирования и неэффективно использует ресурсы (они тоже простаивают), и может применяться только в таких ОС, в которых и расчетный уровень мультипрограммирования невысок.
Залповое выделение.
Процесс должен запрашивать/ освобождать все используемые им ресурсы сразу. Эта стратегия позволяет параллельно выполняться процессам, использующим непересекающиеся подмножества ресурсов. (Процесс C работает с лентой, процесс D - с принтером.) Тупики по-прежнему невозможны, однако неоправданное удерживание ресурсов продолжается. Так, если процессу в ходе выполнения нужны ресурсы R1 и R2, причем ресурс R1 он использует все время своего выполнения t1, а ресурс R2 требуется ему только на время t2<<t1, то процесс вынужден удерживать за собой и ресурс R2 в течение всего времени t1.
В рамках залповой стратегии возможны два варианта: выделять все ресурсы при создании процесса и освобождать при его завершении или же позволить процессу запрашивать/освобождать ресурсы несколько раз в ходе своего выполнения (но обязательно все "залпом"). Очевидно, что второй вариант более либеральный, так как он позволяет уменьшить интервал времени удерживания ресурсов и разнести использование разных ресурсов по разным "залпам". Интересны различия в API для этих двух вариантов. В первом случае требования на ресурсы могут быть вообще вынесены за пределы программного кода процесса и задаваться во внешних описателях процесса (например, в языке управления заданиями). Во втором случае системный вызов getResource является обязательным, причем обязательно должна быть обеспечена возможность запроса в одном вызове ресурсов разных классов и выделение всех запрошенных ресурсов одной непрерываемой операцией.
Иерархическое выделение.
Все классы ресурсов разбиваются по уровням с номерами от 1 до N, каждый уровень содержит только один класс. Процесс имеет право запрашивать ресурсы только из классов с более высокими номерами, чем у тех, которыми он уже владеет. Эта стратегия также предотвращает возникновение тупиков. В каждый момент времени в системе один или несколько процессов имеют класс закрепленных за ними ресурсов выше, чем у других. Эти процессы, обладающие ресурсами высокого уровня, могут беспрепятственно выполняться и завершиться без блокировки.
Следовательно, в каждый момент времени имеется хотя бы один способный к выполнению процесс. Если не будут поступать новые процессы, то все процессы, уже имеющиеся в системе, в конце концов завершатся - тупик отсутствует. Хотя в иерархической стратегии процесс ограничен в последовательности запросов и возможна ситуация, в которой он должен удерживать за собой ресурс более длительное время, чем это действительно необходимо, эта стратегия позволяет достичь неплохой эффективности, особенно при правильном распределении ресурсов по уровням. Целесообразно более высокие уровни назначать более дефицитным и более дорогостоящим ресурсам; как правило, и использование таких ресурсов является более скоротечным. Иерархическую стратегию применяет, например, OS/390 применительно к некоторым системным структурам данных.
Иерархическая стратегия является самой либеральной из стратегий, предотвращающих возникновение тупиков без дополнительной информации. Более либеральные стратегии предотвращения требуют предварительного знания о характеристиках процессов.
Предварительные заявки и алгоритм банкира.
Эта стратегия названа так потому, что действия ОС напоминают действия банкира, выдающего ссуды клиентам, именно на таком примере эта стратегия была рассмотрена в первоисточнике [7]. Применение этой стратегии требует, чтобы процесс передал ОС "предварительную заявку" (advanced claim) и в ней указал максимальный объем ресурсов, который ему понадобится. В ходе выполнения процесс может в произвольном порядке запрашивать/освобождать ресурсы, не выходя, однако, за пределы заявленного объема. Ситуация в системе называется реализуемой, если
- ни одна заявка не превышает общего числа ресурсов в системе;
- ни один процесс не требует большего числа ресурсов, чем им заявлено;
- суммарное число уже распределенных всем процессов ресурсов не превосходит общего числа ресурсов в системе.
Ситуация называется безопасной, если процессы можно выстроить в такую последовательность, что:
- первый процесс может нормально завершиться даже, если он полностью выберет ресурсы по своей заявке;
- второй процесс может нормально завершиться даже, если он полностью выберет ресурсы по своей заявке, при условии, что завершится первый процесс и освободит удерживаемые им ресурсы;
- i-й процесс может нормально завершиться даже, если он полностью выберет ресурсы по своей заявке, при условии, что завершится i-1-й процесс и освободит удерживаемые им ресурсы.
В противном случае ситуация называется опасной.
Если ситуация безопасна, то при отсутствии новых процессов все уже имеющиеся процессы могут нормально завершится, выбрав ресурсы в соответствии со своими заявками, - тупик невозможен.
Пример представлен на Рисунке 5.3.: пусть у ОС имеется всего 12 ресурсов одного класса и на текущий момент выполняются три процесса - P1, P2 и P3, их заявки составляют 12, 4 и 8 ресурсов соответственно. На текущий момент времени процессу P1 выделено 4 ресурса, процессу P2 - 2, процессу P3 - 4 - Рис.5.3.а. В резерве ОС остаются, таким образом, 2 ресурса. Ситуация Рис.5.3.а является безопасной. ОС может выделить оставшиеся два ресурса процессу P2, и этот процесс, полностью получив по своей заявке, может завершится, тогда системный резерв увеличится до 4 ресурсов. Этот резерв ОС отдаст процессу P3, он, завершившись, передаст в резерв ОС 8 ресурсов, которых будет достаточно для удовлетворения заявки процесса P1. Ситуация станет опасной, если ОС выделит ресурс какому-либо другому процессу, кроме P2 - см.Рис.5.3.б. В этой ситуации ОС за счет своего резерва не может полностью удовлетворить ни одну заявку.
 а) безопасная  б) опасная Рис.5.3. Анализ ситуации |
- Создать список, элементами которого являются процессы с их ресурсами и заявками.
- Если список пуст, - установить флаг безопасной ситуации и перейти к п. 7.
- Найти в списке процесс, заявка которого может быть удовлетворена из системного резерва.
- Если такой процесс не найден, - установить флаг опасной ситуации и перейти к п.7.
- Удалить найденный процесс из списка и передать те ресурсы, которыми он обладал в системный резерв.
- Перейти к п.2.
- Закончить проверку.
Алгоритм Габермана.
Другая алгоритмическая реализация стратегии с предварительными заявками известна как алгоритм Габермана. Этот алгоритм иллюстрируется следующим программным листингом:
/* Алгоритм Габермана */ static int S[r]; /* Начальные установки */ void HabervanInit(void) { int i; for (i=0; i<r; S[i++]=0); } /* Выделение ресурса */ int HabermanGet(int claim, int hold) { int i; for (i=0; i<claim-hold; i++) if (!S[i]) return -1; /* отказ */ for (i=0; i<claim-hold; S[i++]--); return 0; /* подтверждение */ } /* Освобождение ресурса */ void HabermanRelease(int claim, int hold) { int i; for (i=0; i<=claim-hold; S[i++]++); }
Если в системе имеется r ресурсов одного класса, то ОС создает массив S из r целых чисел. В ходе начальных установок в массив записывается убывающая последовательность чисел от r до 1. Если процесс, имеющий заявку на claim ресурсов и уже получивший hold ресурсов, запрашивает еще один ресурс, то (функция HabervanGet) все элементы массива S с номерами от 0 до claim-hold-1 включительно уменьшаются на 1. Индикатором опасного состояния является отрицательное значение любого элемента массива S.
На Рисунке 5.4 показана работа алгоритма Габермана для ситуации, рассмотренной нами в примере выше. В графе "Событие" таблицы на рисунке указывается идентификатор процесса, которому выделяется единица ресурса; остальная часть каждой строки представляет состояние массива S после этого выделения. Строка "итог" показывает состояние на момент, когда ресурсы распределены так, как показано на Рис.5.3.а. (Убедитесь сами, что на конечное состояние массива S не влияет последовательность, в которой ресурсы выделялись.) Три нижние строки, в которых идентификатору процесса предшествует символ '*', показывают состояние массива S для альтернативных вариантов - выделения еще одного ресурс процессу P1 или P2, или P3. Видно, что только процесс P2 может получать ресурсы, не переводя систему в опасное состояние.
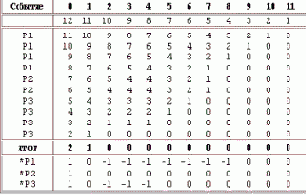 Рис.5.4. Алгоритм Габермана |
При наличии в системе нескольких классов безопасность во всех классах по отдельности не гарантирует безопасности всей системы в целом. Так в примере про процессы A и B, использующие принтер и ленту, ситуация является безопасной как по классу принтеров, так и по классу лент, но в комплексе она является тупиковой. Алгоритм "проигрывания ситуации", требует значительного объема вычислений, но обеспечивает комплексный анализ безопасности.
Отметим, что алгоритм банкира, хотя и является значительно более либеральным, чем все рассмотренные выше, тоже не обеспечивает оптимального уровня мультипрограммирования. Опасная ситуация еще не является тупиковой. Так, ситуация, представленная на Рис.5.3.б, еще может разрядиться, если процесс P1 освободит хотя бы один из удерживаемых им ресурсов. ОС же в оценке ситуации исходит из прогноза о наихудшем развитии ситуации - предположения о том, что процессы будут только запрашивать ресурсы, а не освобождать их.
Возможны и стратегии, обеспечивающие еще более либеральную политику, но они требуют большей предварительной информации о процессе и, как правило, - большего объема вычислений при реализации стратегии. Например, нетрудно представить себе, что если ОС заранее знает, в какой последовательности процесс будет запрашивать/освобождать ресурсы, то она может обеспечить более эффективное управление ими. Но часто ли такая последовательность может быть известна заранее? Среди авторов [8, 20, 27 и др.] нет даже единодушного мнения о том, реально ли требовать от процесса предварительной заявки. На наш взгляд, однако, такое требование в большинстве случаев реально выполнимо: для пакетных процессов потребность в ресурсах бывает известна заранее, интерактивные же процессы в многопользовательских системах запускаются только зарегистрированными пользователями, указанный при регистрации пользователя доступный ему объем ресурсов может считаться такой заявкой.
Двигаясь дальше в сторону либерализации, мы пересекаем ту границу, до которой можно было предотвратить тупики.
Теперь тупики возможны. И теперь ведущее значение приобретают методы обнаружения тупиков.
Определение нетупиковой ситуации очень похоже на определение безопасной ситуации, но отличается тем, что здесь рассматриваются не потенциальные запросы - заявки, а текущие - уже сделанные, но еще не удовлетворенные запросы. Ситуация называется нетупиковой, если процессы можно выстроить в такую последовательность, что:
- первый процесс может получить ресурсы по всем своим текущим запросам;
- второй процесс может получить ресурсы по всем своим текущим запросам при условии, что первый процесс закончился и освободил все выделенные ему ресурсы;
- i-й процесс может получить ресурсы по всем своим текущим запросам при условии, что i-1-й процесс закончился и освободил все выделенные ему ресурсы.
В противном случае ситуация является тупиковой.
Если анализ опасной ситуации исходит из предположения о худшем развитии событий, то анализ тупиковой - из предположения о лучшем их развитии - что процессы больше не будут запрашивать ресурсы, а будут только их освобождать.
Пусть в системе имеется 11 ресурсов одного класса, как представлено на Рисунке 5.5. Процесс P1 уже имеет 2 ресурса и запрашивает еще 2, процесс P2 уже имеет 3 и запрашивает еще 5, процесс P3 имеет 4 и запрашивает еще 4. Системный резерв - 2 ресурса. В зависимости от того, какие у процессов максимальные заявки (нам это неизвестно), ситуация может быть расценена как опасная или безопасная, но она определенно не является тупиковой. Процесс P1 может получить требуемые ресурсы, если он после этого закончится, то может быть удовлетворен запрос процесса P3, а после его завершения - процесса P2. Но если мы выделим еще хотя бы один ресурс процессу P3, ситуация станет тупиковой.
 а) нетупиковая.  a) б) тупиковая. Рис.5.5. Анализ ситуации |
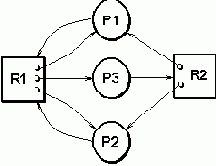 Рис.5.6. Граф ресурсов и процессов |
Дуги графа могут соединять только разнотипные вершины. Направленность дуг означает: от ресурса к процессу - ресурс выделен данному процессу, от процесса к ресурсу - процесс запрашивает ресурс. Признаком тупика является наличие в графе петли - такого пути, который начинается и заканчивается в одной вершине и из которого нет выхода. Так, на Рис. 5.5 представлена тупиковая ситуация: следование по графу любыми возможными путями заставит нас проходить одни и те же вершины. Если же мы уберем дугу, ведущую от процесса P3 к ресурсу R2, то появится выход из петли в вершину P3. Обнаружение тупика сводится к попытке редукции (сокращения) графа. Из графа удаляются те вершины-процессы, которые не имеют запросов или запросы которых могут быть удовлетворены. При этом сокращаются также и все дуги, связанные с этими вершинами. За счет освободившихся ресурсов появляется возможность сократить новые вершины-процессы и т.д. Если в графе нет петель, то после многократных сокращений нам удастся сократить все вершины-процессы.
Как часто следует выполнять проверку тупика? Обратим внимание на то, что если конструктор ОС отказывается от предупреждения тупиков, то он делает это в значительной степени из нежелания загружать систему значительным объемом вычислений по анализу безопасности при каждом запросе. Обнаружение тупика выполняется сходным образом с анализом безопасной ситуации и требует такого же объема вычислений, следовательно, желательно выполнять его как можно реже. Единственным событием, которое может перевести систему из нетупикового состояния в тупиковое, является поступление запроса, который не может быть удовлетворен. Следовательно, попытку обнаружения тупика надо производить только по этому событию, никак не чаще. В некоторых реализациях ОС применяет еще более ленивую политику. Неудовлетворенный запрос может привести к тупику, но может и не привести. "Ленивая" ОС не спешит выполнять проверку даже при поступлении такого запроса, а выжидает некоторое время: может быть "все само собой уладится" - и в большинстве случаев именно так и случается.
И только, если запрос остается неудовлетворенным в течение определенного времени, ОС принимается за поиск тупика. Размер временной выдержки может определяться скоростными характеристиками запрашиваемого ресурса.
Если тупик обнаружен, то как его ликвидировать? К сожалению, развязка тупика практически всегда связана с потерями. Единственным реальным способом развязки является принудительное прекращение одного или нескольких процессов и освобождение удерживаемых ими ресурсов. Как выбрать жертву для прекращения? Во-первых, ОС, конечно, должна быть уверена в том, что при прекращении выбранных процессов освободится объем ресурсов, достаточный для развязки тупика. Во-вторых, оценивается объем потерь, связанных с прекращением того или иного процесса. Прекращенный процесс, скорее всего, будет запущен повторно, таким образом, ресурсы, использованные им при его незаконченном выполнении, составляют прямые потери. Поэтому естественным решением представляется прекращение того процесса, который к этому моменту использовал меньше всего ресурсов (не только монопольных, но любых ресурсов вообще). Поскольку самым дорогостоящим ресурсом обычно является процессорное время, выбор жертвы по критерию минимального использованного времени производится наиболее часто.
Желательно, чтобы "пострадавший" процесс был снова запущен, причем, возможно даже, с повышенным приоритетом. Но всякий ли процесс можно прервать на середине, а потом запустить сначала? Представьте себе процесс-программу, которая должна начислить взносы на 10 банковских счетов. Эта программа принудительно завершается в тот момент, когда она успела обработать только 5 счетов. Если при перезапуске программа начнет выполняться с начала, она повторно начислит взносы на первые 5 счетов. ОС не может знать, приведет ли перезапуск процесса к нежелательным последствиям, поэтому решение о повторном запуске обычно перекладывается на пользователя.
